


My name is Melissa James, and I’m the Metadata Manager at CMU Libraries. That means I am the primary person responsible for maintaining the metadata of the University Library’s collections. But, what is metadata? And, what is library metadata specifically?
A very simple definition of metadata is that metadata is data about data. It is data that describes other data. As an example, consider streaming music files. The song file itself is the data. The song title, artist, album name, and track number are all metadata.
In the Libraries, we use several types of metadata to connect users with the resources they need, but the most common type is called bibliographic or descriptive metadata. This is metadata that describes a book or other library resources such as the title, author, and publisher.
In our current library discovery system Smart Search, descriptive metadata looks like this:

Descriptive metadata for Bring your brain to work by Art Markman as viewed via CMU Libraries’ Smart Search interface.
But, when I came to CMU as an undergraduate in the mid-1990s, we were in the process of transitioning away from metadata that looked like this:
A catalog card containing descriptive metadata of the book Louisa May Alcott by Susan Cheever. This card contains a physical description of the book as well as the international book standard number (ISBN), subject headings, and Library of Congress call number.

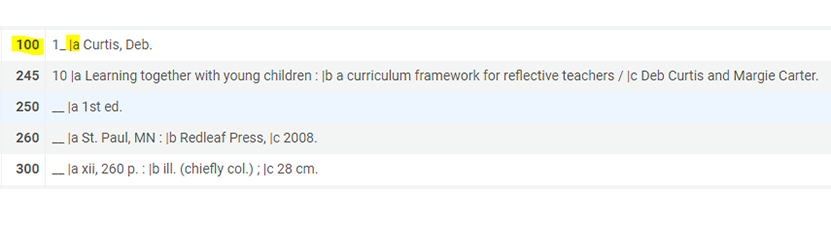
To get from catalog cards to the sophisticated discovery tools of today, librarians in the 1960s developed structural metadata called MARC or Machine Readable Cataloging, which allowed them to transform catalog card data into computerized metadata.
A section of the bibliographic record for Learning together with young children by Deb Curtis and Margie Carter. The numbered MARC “tags” going down the left of the page along with the subfield “delimiters”, pipe characters followed by a single lower-case letter, allowed the data to be read and processed by computers.
These days we are in the very early stages of transitioning again to a new metadata standard called BIBFRAME that will be both structural and descriptive. The new standard is more flexible and dynamic. It will transform CMU Libraries’ metadata, making it indexable by web browsers. In the future, this will improve our user’s search experience by making CMU Libraries’ individual resources easily found on the open web.
BIBFRAME is currently in advanced development and testing at the Library of Congress. You can read more about it here.
A section of the bibliographic record for Learning together with young children by Deb Curtis and Margie Carter. The BIBFRAME tags enclosed in the arrow brackets will allow the data to eventually be indexed by web browsers.

To learn more about our work, see What exactly is Acquisitions and Metadata Services by Amie Pifer.
So much easier to use than the old method I learned on. What a lot of thought and work that must have gone into getting this up and running. Libraries are so much more than just books. They are almost a living thing changing, evolving and improving each day. Liberians are the organizers of knowledge.